Introduction to timeseries plots in Python
Imports
1
2
3
4
5
6
7
8
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
from datetime import date
from nsepy import get_history
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# NIFTY 50 index
nifty_50 = get_history(symbol="NIFTY 50",
start=date(2001,1,1),
end=date(2020,5,3),
index=True)
# NIFTY Next 50 index
nifty_next50 = get_history(symbol="NIFTY NEXT 50",
start=date(2001,1,1),
end=date(2020,5,3),
index=True)
# India VIX index
india_vix = get_history(symbol="INDIAVIX",
start=date(2001,1,1),
end=date(2020,5,3),
index=True)
1
nifty_50.shape, nifty_next50.shape, india_vix.shape
1
((4806, 6), (4806, 6), (2796, 7))
1
MKT = nifty_next50.join(nifty_50['Close'], how='outer', rsuffix='_N50').dropna()
1
2
3
data = MKT.rename(columns={'Close':'NN50','Close_N50':'N50'})\
.assign(NN50_returns=lambda x: np.log(x['NN50']/x['NN50'].shift(1)))\
.assign(N50_returns=lambda x: np.log(x['N50']/x['N50'].shift(1)))
1
data = data[['NN50', 'N50', 'NN50_returns', 'N50_returns']].dropna()
1
data.index = pd.DatetimeIndex(data.index)
1
2
3
4
5
6
7
# Let's plot SPX and VIX cumulative returns with recession overlay
plot_cols = ['NN50', 'N50']
# 2 axes for 2 subplots
fig, axes = plt.subplots(2,1, figsize=(10,7), sharex=True)
data[plot_cols].plot(subplots=True, ax=axes)
1
2
3
array([<matplotlib.axes._subplots.AxesSubplot object at 0x11b5f6610>,
<matplotlib.axes._subplots.AxesSubplot object at 0x11a0cf8d0>],
dtype=object)
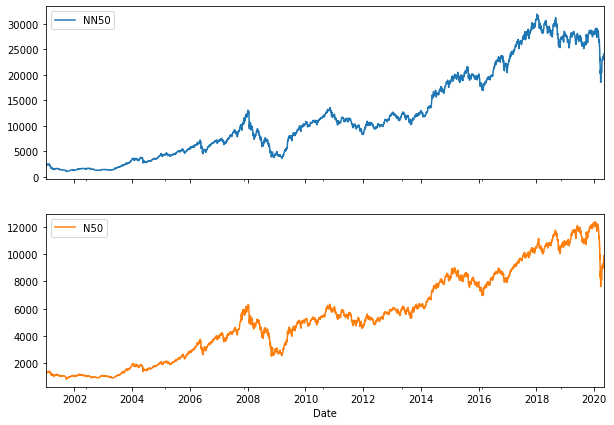
1
2
3
4
5
6
7
# Let's plot SPX and VIX cumulative returns with recession overlay
plot_cols = ['NN50_returns', 'N50_returns']
# 2 axes for 2 subplots
fig, axes = plt.subplots(2,1, figsize=(10,7), sharex=True)
data[plot_cols].plot(subplots=True, ax=axes)
1
2
3
array([<matplotlib.axes._subplots.AxesSubplot object at 0x11669c550>,
<matplotlib.axes._subplots.AxesSubplot object at 0x115ccc090>],
dtype=object)
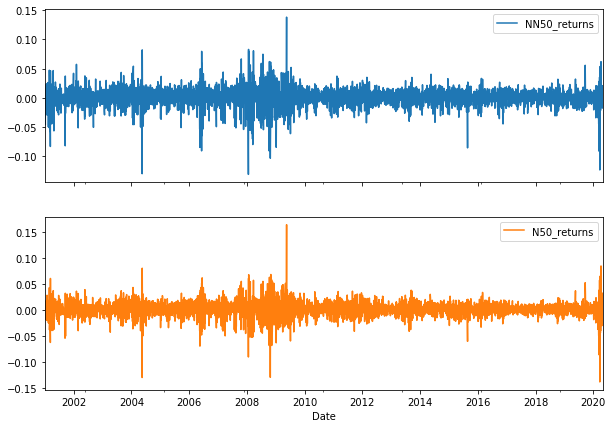
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# ================================================================== #
# resample log returns weekly starting monday
lrets_resampled = data[['NN50_returns', 'N50_returns']].resample('W-MON').sum()
# ================================================================== #
# rolling mean returns
n = 52
roll_mean = lrets_resampled.rolling(window=n, min_periods=n ).mean().dropna(axis=0,how='all')
# ================================================================== #
# rolling sigmas
roll_sigs = lrets_resampled.rolling(window=n, min_periods=n ).std().dropna(axis=0,how='all') * math.sqrt(n)
# ================================================================== #
# rolling risk adjusted returns
roll_risk_rets = roll_mean/roll_sigs
1
2
3
4
5
6
7
# Let's plot SPX and VIX cumulative returns with recession overlay
plot_cols = ['NN50_returns', 'N50_returns']
# 2 axes for 2 subplots
fig, axes = plt.subplots(2,1, figsize=(10,7), sharex=True)
roll_mean[plot_cols].plot(subplots=True, ax=axes)
1
2
3
array([<matplotlib.axes._subplots.AxesSubplot object at 0x1165e9b50>,
<matplotlib.axes._subplots.AxesSubplot object at 0x11738d190>],
dtype=object)
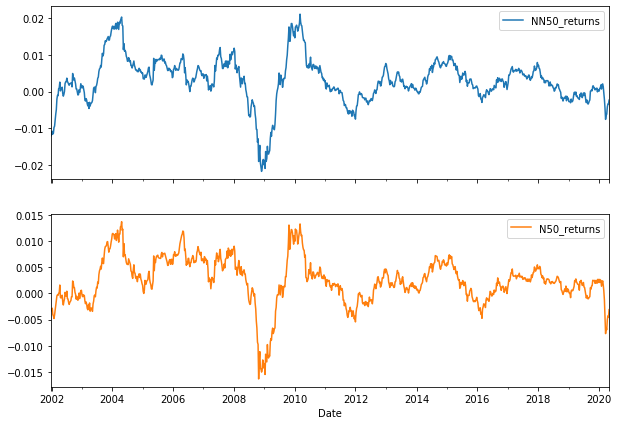
1
2
3
4
data[['NN50', 'N50']].rolling(250).mean().head()
# \
# .assign(NN50_returns=lambda x: np.log(x['NN50']/x['NN50'].shift(1)))\
# .assign(N50_returns=lambda x: np.log(x['N50']/x['N50'].shift(1)))
| NN50 | N50 | |
|---|---|---|
| Date | ||
| 2001-01-02 | NaN | NaN |
| 2001-01-03 | NaN | NaN |
| 2001-01-04 | NaN | NaN |
| 2001-01-05 | NaN | NaN |
| 2001-01-08 | NaN | NaN |
1
2
%load_ext watermark
%watermark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
The watermark extension is already loaded. To reload it, use:
%reload_ext watermark
2020-05-04T08:30:27+05:30
CPython 3.7.4
IPython 7.9.0
compiler : Clang 4.0.1 (tags/RELEASE_401/final)
system : Darwin
release : 19.4.0
machine : x86_64
processor : i386
CPU cores : 4
interpreter: 64bit
1